Should I learn how to use Snowflake?
Snowflake has been gaining rapidly in popularity in recent years, and it's easy to see why. It's fast, scalable, accessible, secure, and cost-effective. Once you've had a taste of what Snowflake brings, it's difficult to go back to the traditional way of doing data warehousing.
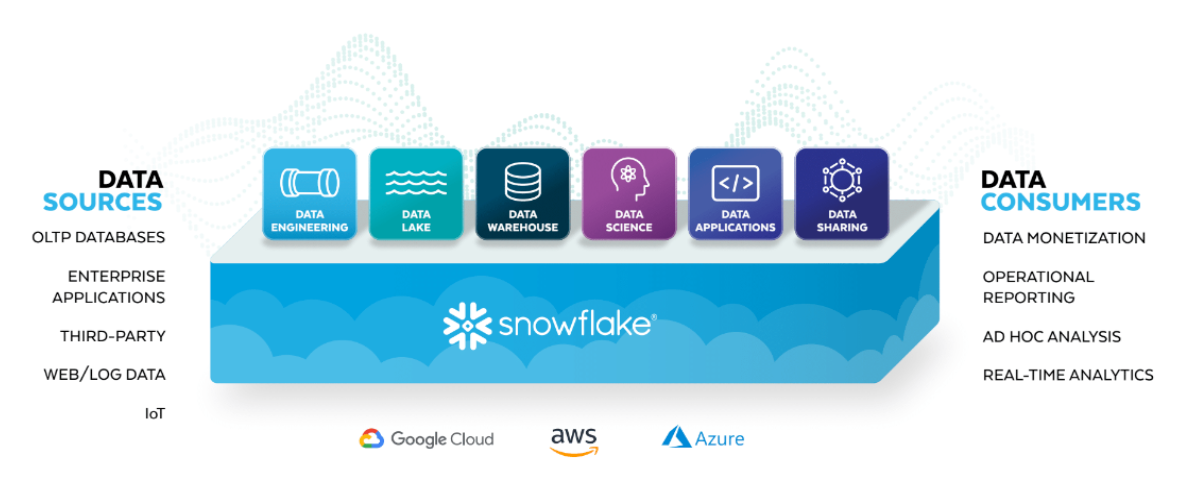
Maybe you're thinking: "That all sounds fantastic, but it must be difficult to set it up and to use it properly." After all, setting up a proper data warehouse has never been an easy task. Perhaps you have tried your hand at some other technologies, such as Spark or Hadoop, which have a steep learning curve, because you have to learn new syntax.
Snowflake, on the other hand, is fully SQL-based. Odds are, if you have some experience in BI or data analysis, you've already worked with SQL before. Most of what you already know can be applied to Snowflake.
The content in this blog post is not intended to be a complete user guide, as it only highlights certain aspects of Snowflake. If you are looking for a guide, I recommend the following resources:
A series of blog posts written by my colleague Issye:
- Blog | Snowflake 101: Why is Snowflake Great? (1/4)
- Blog | Snowflake 101: Setting Up Environment and Database (2/4)
- Blog | Snowflake 101: Loading Data from Local (3/4)
- Blog | Snowflake 101: Loading Data from Cloud using AWS (4/4)
- Blog | How to pass the SnowPro Core certification exam
- Official Snowflake training portal | Snowflake University
Signing up for Snowflake
We'll first need to sign up for an account (if you don't have one already). Snowflake offers a pretty generous free trial, so it's a great way to see for yourself what Snowflake has to offer.
Want to try out Snowflake? We got you covered! Sign up for a Snowflake trial today and receive $400 worth of free usage when you test drive Snowflake.
This is where you get your first taste of how easy it is to work with Snowflake. You register for an account, and after receiving the confirmation email, you can choose a username and password, and that's pretty much it! You don't have to go through any additional installation steps or configure any other settings before you are ready to go.
Querying Data
Once you've logged into the web portal, you'll be greeted with an UI that feels pretty familiar if you've worked with a SQL client before. Your Snowflake account also comes pre-loaded with some sample data which you can find in SNOWFLAKE_SAMPLE_DATA database, so you can start writing some SQL queries right away.
What about some of the more advanced functionality, like querying JSON or geographic data? Snowflake offers these functionalities by extending its SQL syntax, so it's easy to integrate with your regular SQL queries.
For example, suppose you have the following JSON loaded into a table called JSON_DEMO within the special VARIANT column type:
{ "date" : "2021-01-01", "customer" : "John Doe", "product" : "Mobile Phone" }
You can query the table by using the : notation
SELECT json_string:date::date as order_date , json_string:customer::string as customer , json_string:product::string as product FROM json_demo
The :: notation is then used to specify the desired data type. This works seamlessly within regular SQL syntax, so you can easily join this query with your other tables. There's no need to learn additional syntax or to perform complex data transformations upfront. The same applies to most other advanced functions in Snowflake.
Loading Data
At some point you'll want to work with your own data, so how about getting data into Snowflake?
One way to do it is to use the Load Data wizard in the web portal. You select the table you want to load data to, and the wizard will guide you through the options, such as which file you want to load, whether it's a CSV file or some other format, etc.

The wizard works well, but you may want to write code that can be incorporated in your scripts. For example, to load a CSV file into a table called mytable using a table stage:
put file:///data/data.csv @%mytable;copy into mytable file_format = (type = csv field_delimiter = ',' skip_header = 1);
Loading JSON or geographical data is also a cinch. Snowflake provides special data types such as VARIANT or GEOGRAPHY to handle them. For example, you can load an entire JSON file into a table with a VARIANT column, and then use the built-in JSON functions to query the data. Similarly, if you have a GeoJSON file, you can simply load the data into a GEOGRAPHY column.
I won't go into too much detail into all the different options you have for loading data, but it's easy to get whatever data you have on your machine into Snowflake.
Configuring Warehouses
The aforementioned sections primarily look at the user's point of view. But what if I'm responsible for maintaining and configuring the data warehouse? I heard you can scale warehouses up and down, but how do I do that?
Similar to loading data, you can use the wizard to configure (or create) your warehouses.

But you can also use SQL syntax:
alter warehouse compute_wh set warehouse_size= small, auto_suspend = 60, auto_resume = true
If you so desire, you can even incorporate this into your SQL scripts. Let's say your SQL script contains multiple steps, and one of the more intensive steps could benefit from more resources. Just add the appropriate ALTER WAREHOUSE statements in your script. No need to tinker with advanced settings, mess with config files, or restart servers.
Performance Tuning
If you were concerned with performance tuning in other databases before, you may know how difficult this can be. You'll have to decide what indices and distribution keys to create, what statistics to collect, etc, and you may need to monitor and reevaluate these as data volumes grow and new objects are created.
Snowflake uses micro-partitions instead of indices, and it collects the relevant metadata of these micro-partitions to optimize your queries. This is all done automatically, so you’ll get great performance right out of the box, even with large data volumes. You may want to apply clustering in certain cases, but there’s not much more to worry about otherwise.
Conclusion
So there you have it! There's obviously a lot more ground to cover than what is possible in this blog post, but I hope I've convinced you that Snowflake is, in fact, easy to learn due to their SQL-based approach and their commitment to reducing complexity for the user.
So sign up for a trial account, check out the learning resources I mentioned above, and before long, you'll feel right at home in Snowflake!
Build a data-driven organization with Snowflake.
A powerful data cloud thanks to an architecture and technology that enables today’s data-driven organizations.
Want to try out Snowflake? We got you covered! Sign up for a Snowflake trial today and receive $400 worth of free usage when you test drive Snowflake. Don't hesitate to reach out to us if you need some assistance with you setting up your Snowflake trial. We'll get one of our bright minds to help you with it.
![]()
Timothy Vermeiren
Analytics Consultant
Biztory

Discover other Snowflake content
- Technologies - Snowflake
- Blog | Snowflake 101: Why is Snowflake Great? (1/4)
- Blog | Snowflake 101: Setting Up Environment and Database (2/4)
- Blog | Snowflake 101: Loading Data from Local (3/4)
- Blog | Snowflake 101: Loading Data from Cloud using AWS (4/4)
- Blog | What is Snowflake?
- Blog | What are the different Snowflake components?
- Blog | Is Snowflake difficult to learn
- Blog | The Power of Snowflake's Data Sharing
- Blog | Snowflake Security - The essentials
- Blog | How to pass the SnowPro Core certification exam


