Let's start with the basics
What's ETL?
For many years, teams developed data pipelines using an established paradigm. They would extract data from a source system, immediately transform the data, and then load it into a destination, referred to as a data warehouse.
This is called ETL (Extract, Transform and Load).
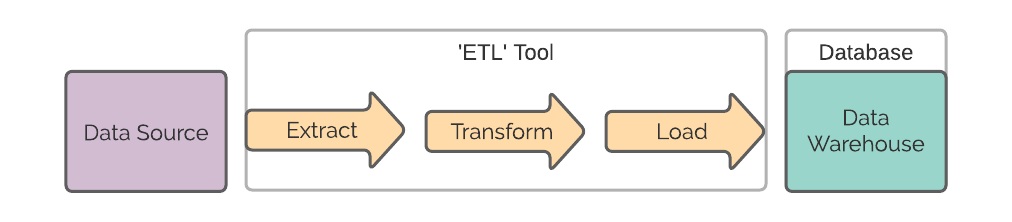
The data warehouse would then power the reporting and analytics activities of the organisation. This approach was traditionally necessary, because the storage in the data warehouse was finite, and it was expensive to maintain enough compute power in the data warehouse to operate on the raw data.
With modern cloud data platforms (e.g. Snowflake) organisations have access to near unlimited storage, as well as cost-effective and flexible compute power.
What's ELT?
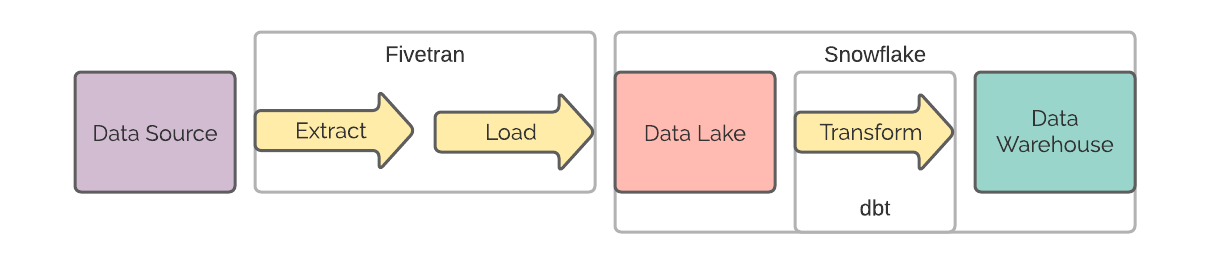
The creation of modern cloud data platforms led to a paradigm shift. Where teams can extract data from a source system, extract and load it directly into what is referred to as a data lake, and then transform it into their data warehouse.
This is called ELT (Extract, Load and Transform).

This means that organisations will always have access to all of their historical data. The data lake can be used for other use cases, such as the application of data science.
At Biztory we help our customers modernise their architecture using this new paradigm, and best-in-class tools.
- We use Fivetran to extract and load the data.
- We then use Snowflake to act as the storage for both the data lake and the data warehouse, as well as providing the compute power for the transformations.
What is dbt?
dbt is then the tool that Biztory uses to manage the ‘logic’ of the transformations between the data lake and the data warehouse.
One benefit of using the ELT paradigm in Snowflake is that the transformations are purely written in SQL. ETL work would often require specialised experience in proprietary tools, which are hard to acquire, whereas SQL skills are ubiquitous in the data industry.
Even within SQL, managing transformations would usually require in-depth knowledge of more complex queries, such as the creation of tables and views, and the insertion, deletion, updates and merges of data in tables.
With dbt we can express all of our analytical logic with simple SELECT statements that every analyst is familiar with. dbt then handles all of the work to ‘materialise’ these into our data warehouse.
Each of these SELECT statements is referred to as a ‘model’. dbt also handles the dependencies between the models. So if I have a ‘product’ model that joins a product table to a category table, this model can then be reused in several other models.
dbt provides other key benefits for ELT workflows:
-
Automated documentation - dbt will generate documentation and diagrams of the SQL models you have created, as well as dependencies between the models.
-
Automated testing - dbt allows you to define tests that can be performed after each transformation. These tests can be as simple as checking that a column contains no nulls, to ensuring referential integrity between tables.
-
Collaboration - Because all the transformations are expressed as code, they can be committed to a version control system like Git. This allows large teams to contribute to the transformation process.
How is dbt used in Fivetran?
dbt will handle the compilation of the code that will be used to transform the data in the data warehouse. But this code will often need to be triggered on a schedule. dbt provides a separate tool to allow this, called dbt Cloud.
Fivetran customers can use dbt Core - which is free and open source - and allow Fivetran to handle the scheduling of the transformations, as well as logging and altering if any issues should occur.
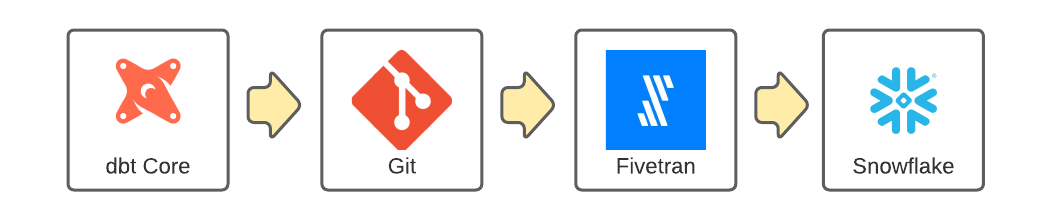
The steps to achieve this are:
-
Models are created locally in a dbt Core project. dbt then compiles these models into SQL statements that will transform the data in the data warehouse.
-
This project is published to a Git repository like Github. This allows teams to collaborate on the project.
-
Fivetran will pull the most recent copy of the transformations from Git.
-
A schedule in Fivetran will periodically execute the SQL code in your Snowflake instance.
At Biztory we believe using an ELT paradigm with dbt at its core helps organisations to modernise and accelerate their analytics activities. If you’d like to learn more about how we can help you, please reach out to us.

Discover other Fivetran content
- Technologies - Fivetran
- Blog | What is Fivetran?
- Blog | Why Fivetran and not another tool?
- Blog | Is ELT better than ETL?
- Blog | How does usage-based pricing of Fivetran work?
- Blog | Biztory named Fivetran EMEA Partner of the Year
Interested to discover more about the modern data stack?
Learn how to connect all your data. In this 30 minute session, we'll uncover how you can access new datasets quickly and easily to supercharge your analysis. Get the skinny on our latest partner technologies and unlock more potential in your data economy.



